tg-me.com/sqlhub/1874
Last Update:
SQL Flow позиционируется как «DuckDB для потоковых данных» — лёгковесный движок stream-обработки, позволяющий описывать весь pipeline единственным языком SQL и служащий компактной альтернативой Apache Flink.
🔍 Ключевые возможности:
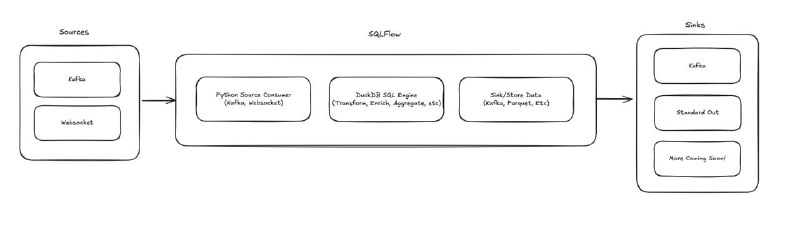
- Источники (Sources): Kafka, WebSocket-стримы, HTTP-webhooks и др.
- Приёмники (Sinks): Kafka, PostgreSQL, локальные и S3-подобные хранилища, любые форматы, которые поддерживает DuckDB (JSON, Parquet, Iceberg и т.д.).
- SQL-обработчик (Handler): встраивает DuckDB + Apache Arrow; поддерживает агрегаты, оконные функции, UDF и динамический вывод схемы.
- Управление окнами: in-memory tumbling-windows, буферные таблицы.
- Наблюдаемость: встроенные Prometheus-метрики (с релиза v0.6.0).
🔗 Архитектура
Конвейер описывается YAML-файлом с блоками `source → handler → sink`.
Во время выполнения:
1. Source считывает поток (Kafka, WebSocket …).
2. Handler выполняет SQL-логику в DuckDB.
3. Sink сохраняет результаты в выбранное хранилище.
# получить образ
docker pull turbolytics/sql-flow:latest
# тестовая проверка конфигурации
docker run -v $(pwd)/dev:/tmp/conf \
-v /tmp/sqlflow:/tmp/sqlflow \
turbolytics/sql-flow:latest \
dev invoke /tmp/conf/config/examples/basic.agg.yml /tmp/conf/fixtures/simple.json
# запуск против Kafka
docker-compose -f dev/kafka-single.yml up -d # поднять Kafka
docker run -v $(pwd)/dev:/tmp/conf \
-e SQLFLOW_KAFKA_BROKERS=host.docker.internal:29092 \
turbolytics/sql-flow:latest \
run /tmp/conf/config/examples/basic.agg.mem.yml --max-msgs-to-process=10000
▪ Github
@sqlhub